A clinical trial generates millions of data points. If this data is unorganized, missing, or full of errors, even a miraculous medical breakthrough can be rejected by global regulatory agencies. Clinical Data Management (CDM) is the engine that converts chaotic clinical trial observations into a clean, high-quality, and structurally sound dataset ready for statistical analysis.
CDM professionals ensure data integrity by acting as the guardians of the trial’s data pipeline. The process requires careful planning and precise technical execution.
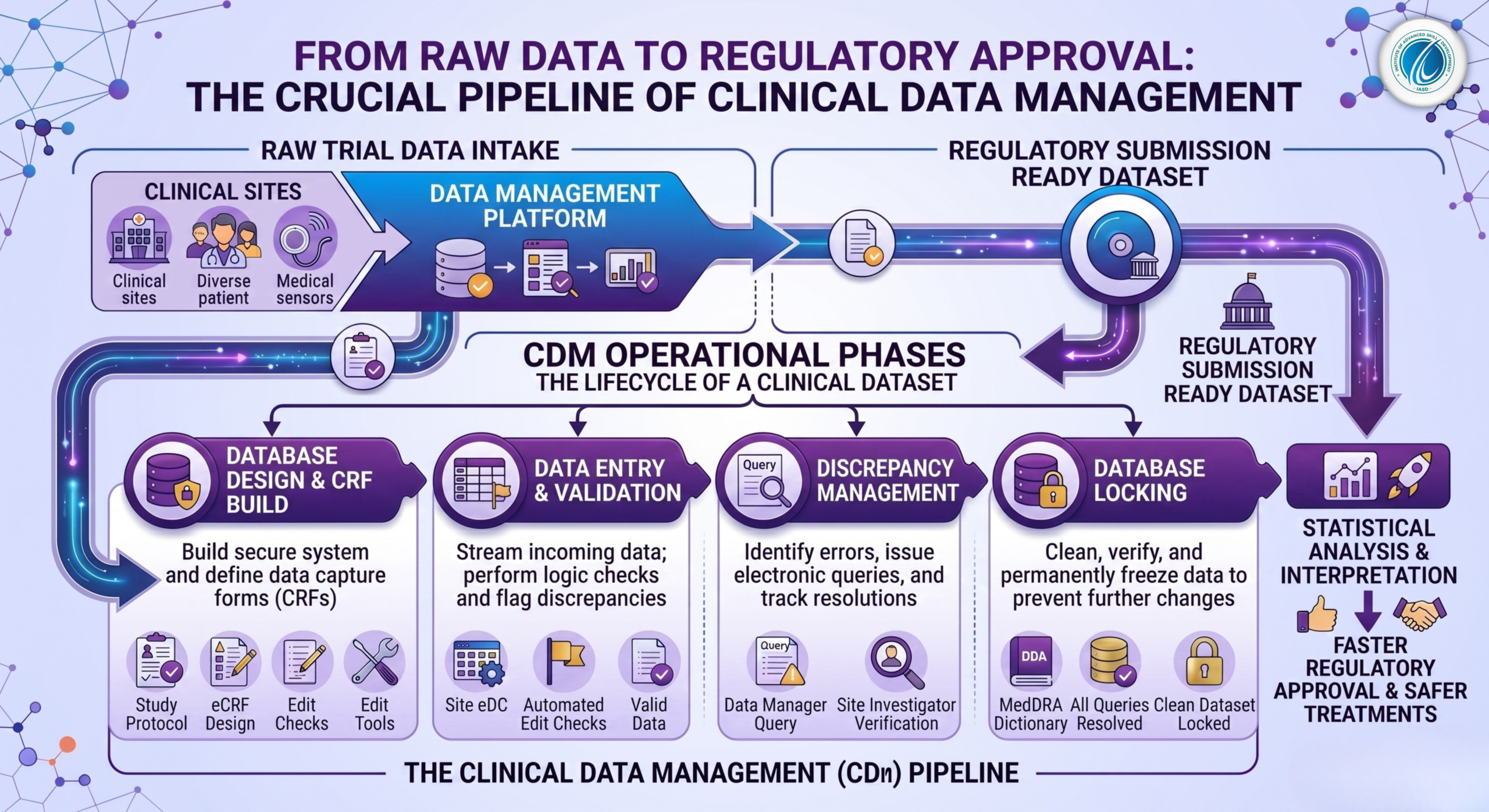
The Lifecycle of a Clinical Dataset
-
Database Design: Long before the first patient is enrolled, CDM teams build a secure electronic database and design Case Report Forms (CRFs) to accurately capture trial metrics.
-
Data Entry & Validation: As data flows from clinical sites, automated edit-check programs flag logical discrepancies (e.g., a male patient marked as pregnant, or a lab value outside physiological limits).
-
Discrepancy Management: When data seems incorrect, data managers issue “queries” to the clinical site, asking investigators to verify or correct the records.
-
Medical Coding: Unstructured text for adverse events and concomitant medications are mapped to standardized global dictionaries like MedDRA and WHODrug.
-
Database Locking: Once all data is clean, validated, and verified, the database is locked to prevent further changes, ensuring the statistical analysis is completely secure and unbiased.
In modern clinical research, CDM is the bedrock of credibility. High-quality data leads to reliable trial outcomes, faster regulatory approvals, and safer treatments reaching patients sooner.